Automating and operationalizing data protection with Dataguise and Microsoft Information Protection
This blog post is part of the Microsoft Intelligent Security Association guest blog series. Learn more about MISA.
In technical literature, the terms data discovery, classification, and tagging are sometimes used interchangeably, but there are real differences in what they actually mean—and each plays a critical role in an enterprise data protection strategy.
Data discovery is the process of reporting information about the sensitivity of a data object. The granularity of reporting typically includes what type of sensitive information is found, exactly where it is found, along with the exact cardinality of sensitive data elements. Data classification is the association of a label, which typically has some business value, to an object (file or a table). Classification is often stored as metadata in a separate system or an external data catalog and enables downstream usage of a data object based on security or privacy policies. Data tagging (labeling) is the application of an actual label (or classification) to the associated object.
The important thing to note here is that data discovery is always foundational to a data protection strategy. Classification and tagging depend on accurate discovery to drive the appropriate method of protection, which will ultimately depend on the consumption or utilization and privacy requirements for the data. The more comprehensive and efficient (automated and integrated) the data discovery, the more effective and cost-effective the data protection.
Dataguise and Microsoft Information Protection: Better together
Now, you probably know that Microsoft Information Protection is a comprehensive suite of services and features that Microsoft offers for its customers to classify, label, and protect data. Microsoft Information Protection forms the core of many enterprise data protection strategies.
Dataguise is a sensitive data discovery and protection software that now integrates with Microsoft Information Protection. More specifically, it performs context-aware discovery of structured, unstructured, and semi-structured data, and can use the results of that discovery to report on data classification, tag data with Microsoft Information Protection-readable labels, and protect sensitive data either natively—via innumerable methods of masking, encryption, and monitoring—or by integrating with Microsoft Information Protection or a third-party data protection solution. It’s a highly scalable solution that relies on machine learning and other heuristics to allow for efficient, accurate data discovery in multi-petabyte, hybrid environments.
With Dataguise, discovery can be done at several levels to meet various risk, compliance, or data governance goals; but there are two kinds of discovery that are of particular interest here, and it’s important to distinguish them:
- Discovery of personal information and other sensitive data: This is the process of finding and reporting data governed by PII, PCI, PHI, and any similar policy, where all sensitive data needs to be discovered but not associated with an individual. Such requirements are typically driven by industry security standards or regulations.
- Identity-based data discovery: This is the process of finding and reporting data specifically related to an individual. The contents of the report may or may not be useful for directly identifying the associated individual, but the entirety of a report constitutes the breadth of information that an enterprise possesses about the given data subject. Identity-based discovery is typically driven by recent data privacy laws like GDPR in the EU, CCPA in California, and LGPD in Brazil.
A data protection strategy that takes both types of discovery into account and incorporates technologies to perform them accurately, efficiently, and comprehensively—can add value not only for information security or privacy teams but for risk, compliance, governance, analytics, marketing, and IT operations teams as well. When you think of all the ways an organization collects, uses, shares, and stores data across the enterprise, more granular visibility leads to more precise control and, therefore, greater business flexibility and agility to maximize data value.
Ultimately, Dataguise complements Microsoft Information Protection capabilities, making the combination extremely useful for the customer.
The discovery synergy: Dataguise augments Microsoft Information Protection scanning capabilities
Dataguise’s real strength lies in the fact that it can discover and report sensitive and personal data across relational databases, NoSQL databases, Hadoop, file shares, cloud stores like ADLS, S3, and GCS, and over 200 different cloud-based applications. Therefore, Dataguise primarily can extend Microsoft Information Protection’s scanning coverage to structured and unstructured data stored outside Microsoft products to the ones mentioned above. This is a game-changer, as Microsoft Information Protection can now be used to tag all co-located sensitive and personal data on all co-located platforms.
The protection synergy: Dataguise enhances downstream data protection capabilities for Microsoft Information Protection
Dataguise uses Microsoft Information Protection’s SDK to seamlessly integrate discovery with Microsoft Information Protection’s tagging capability. Whether the tags power DLP, access control, or encryption and decryption solutions, Dataguise can either natively or by leveraging a third-party solution, team up with Microsoft Information Protection to create an end-to-end data protection strategy and automated implementation.
So how does this all work?
The integration is seamless and starts with defining the tags in Microsoft Information Protection. Then, there is a mapping of these tags to one or a combination of sensitive elements, out-of-the-box or custom in Dataguise. As Dataguise runs its discovery scans, it is using that mapping to report tags corresponding to each file that it has scanned. Now, using the Microsoft Information Protection SDK, these tags are applied to the corresponding file. Dataguise discovery uses context-aware discovery based on machine learning, which benefits Microsoft Information Protection by tagging files accurately and at scale. The figure below shows the flow:
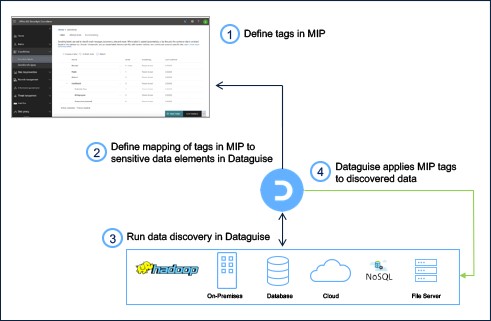
Dataguise and Microsoft Information Protection bring a powerful combination of capabilities to any data protection strategy and implementation. The joint value of this integration lies in the fact that Dataguise can cover a broad range of platforms for discovery, and then leverage Microsoft Information Protection labeling to enable downstream data protection. Intelligent and context-aware data discovery is foundational to data protection, and with accurate optics, enterprise-wide implementation of comprehensive and automated data protection policies can be achieved.
For more information about the Dataguise Sensitive Data Discovery and Protection solution, please visit www.dataguise.com. You can also find Dataguise on the Azure Marketplace.
Learn more
To learn more about the Microsoft Intelligent Security Association (MISA), visit our website where you can learn about the MISA program, product integrations, and find MISA members. Visit the video playlist to learn about the strength of member integrations with Microsoft products.
For more information about Microsoft Security Solutions, visit the Microsoft Security website. Bookmark the Security blog to keep up with our expert coverage of security matters. Also, follow us at @MSFTSecurity for the latest news and updates on cybersecurity.
READ MORE HERE