Researchers Create an AI Cyber Defender That Reacts to Attackers
A newly created artificial intelligence (AI) system based on deep reinforcement learning (DRL) can react to attackers in a simulated environment and block 95% of cyberattacks before they escalate.
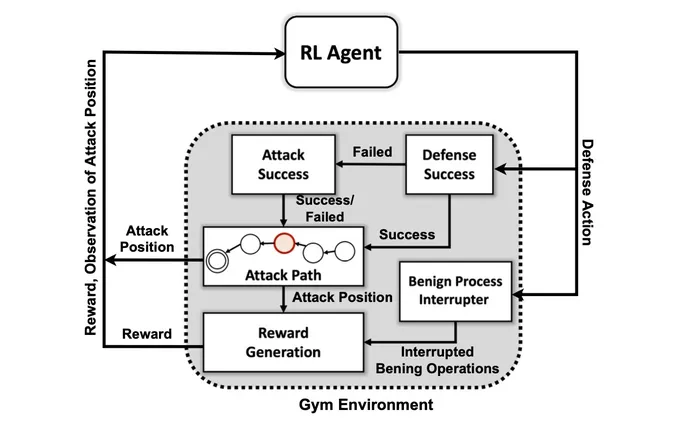
That’s according to the researchers from the Department of Energy’s Pacific Northwest National Laboratory who built an abstract simulation of the digital conflict between attackers and defenders in a network and trained four different DRL neural networks to maximize rewards based on preventing compromises and minimizing network disruption.
The simulated attackers used a series of tactics based on the MITRE ATT&CK framework’s classification to move from the initial access and reconnaissance phase to other attack phases until they reached their goal: the impact and exfiltration phase.
The successful training of the AI system on the simplified attack environment demonstrates that defensive responses to attacks in real time could be handled by an AI model, says Samrat Chatterjee, a data scientist who presented the team’s work at the annual meeting of the Association for the Advancement of Artificial Intelligence in Washington, DC on Feb. 14.
“You don’t want to move into more complex architectures if you cannot even show the promise of these techniques,” he says. “We wanted to first demonstrate that we can actually train a DRL successfully and show some good testing outcomes, before moving forward.”
The application of machine learning and artificial intelligence techniques to different fields within cybersecurity has become a hot trend over the past decade, from the early integration of machine learning in email security gateways in the early 2010s to more recent efforts to use ChatGPT to analyze code or conduct forensic analysis. Now, most security products have — or claim to have — a few features powered by machine learning algorithms trained on large datasets.
Yet creating an AI system capable of proactive defense continues to be aspirational, rather than practical. While a variety of hurdles remain for researchers, the PNNL research shows that an AI defender could be possible in the future.
“Evaluating multiple DRL algorithms trained under diverse adversarial settings is an important step toward practical autonomous cyber defense solutions,” the PNNL research team stated in their paper. “Our experiments suggest that model-free DRL algorithms can be effectively trained under multi-stage attack profiles with different skill and persistence levels, yielding favorable defense outcomes in contested settings.”
How the System Uses MITRE ATT&CK
The first goal of the research team was to create a custom simulation environment based on an open source toolkit known as Open AI Gym. Using that environment, the researchers created attacker entities of different skill and persistence levels with the ability to use a subset of 7 tactics and 15 techniques from the MITRE ATT&CK framework.
The goals of the attacker agents are to move through the seven steps of the attack chain, from initial access to execution, from persistence to command and control, and from collection to impact.
For the attacker, adapting their tactics to the state of the environment and the defender’s current actions can be complex, says PNNL’s Chatterjee.
“The adversary has to navigate their way from an initial recon state all the way to some exfiltration or impact state,” he says. “We’re not trying to create a kind of model to stop an adversary before they get inside the environment — we assume that the system is already compromised.”
The researchers used four approaches to neural networks based on reinforcement learning. Reinforcement learning (RL) is a machine learning approach that emulates the reward system of the human brain. A neural network learns by strengthening or weakening certain parameters for individual neurons to reward better solutions, as measured by a score indicating how well the system performs.
Reinforcement learning essentially allows the computer to create a good, but not perfect, approach to the problem at hand, says Mahantesh Halappanavar, a PNNL researcher and an author of the paper.
“Without using any reinforcement learning, we could still do it, but it would be a really big problem that will not have enough time to actually come up with any good mechanism,” he says. “Our research … gives us this mechanism where deep reinforcement learning is sort of mimicking some of the human behavior itself, to some extent, and it can explore this very vast space very efficiently.”
Not Ready for Prime Time
The experiments found that a specific reinforcement learning method, known as a Deep Q Network, created a strong solution to the defensive problem, catching 97% of the attackers in the testing data set. Yet the research is only the start. Security professionals should not look for an AI companion to help them do incident response and forensics anytime soon.
Among the many problems that remain to be solved is getting reinforcement learning and deep neural networks to explain the factors that influenced their decisions, an area of research called explainable reinforcement learning (XRL).
In addition, the robustness of the AI algorithms and finding efficient ways of training the neural networks are both problems that need to be solved, says PNNL’s Chatterjee.
“Creating a product— that was not the main motivation for this research,” he says. “This was more about scientific experimentation and algorithmic discovery.”
Read More HERE