Lessons learned from the Microsoft SOC—Part 3c: A day in the life part 2

This is the sixth blog in the Lessons learned from the Microsoft SOC series designed to share our approach and experience from the front lines of our security operations center (SOC) protecting Microsoft and our Detection and Response Team (DART) helping our customers with their incidents. For a visual depiction of our SOC philosophy, download our Minutes Matter poster.
COVID-19 and the SOC
Before we conclude the day in the life, we thought we would share an analyst’s eye view of the impact of COVID-19. Our analysts are mostly working from home now and our cloud based tooling approach enabled this transition to go pretty smoothly. The differences in attacks we have seen are mostly in the early stages of an attack with phishing lures designed to exploit emotions related to the current pandemic and increased focus on home firewalls and routers (using techniques like RDP brute-forcing attempts and DNS poisoning—more here). The attack techniques they attempt to employ after that are fairly consistent with what they were doing before.
A day in the life—remediation
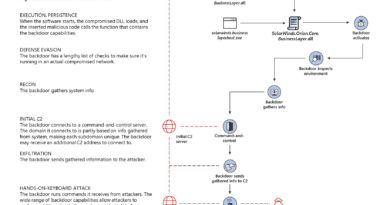
When we last left our heroes in the previous entry, our analyst had built a timeline of the potential adversary attack operation. Of course, knowing what happened doesn’t actually stop the adversary or reduce organizational risk, so let’s remediate this attack!
- Decide and act—As the analyst develops a high enough level of confidence that they understand the story and scope of the attack, they quickly shift to planning and executing cleanup actions. While this appears as a separate step in this particular description, our analysts often execute on cleanup operations as they find them.
Big Bang or clean as you go?
Depending on the nature and scope of the attack, analysts may clean up attacker artifacts as they go (emails, hosts, identities) or they may build a list of compromised resources to clean up all at once (Big Bang)
- Clean as you go—For most typical incidents that are detected early in the attack operation, analysts quickly clean up the artifacts as we find them. This rapidly puts the adversary at a disadvantage and prevents them from moving forward with the next stage of their attack.
- Prepare for a Big Bang—This approach is appropriate for a scenario where an adversary has already “settled in” and established redundant access mechanisms to the environment (frequently seen in incidents investigated by our Detection and Response Team (DART) at customers). In this case, analysts should avoid tipping off the adversary until full discovery of all attacker presence is discovered as surprise can help with fully disrupting their operation. We have learned that partial remediation often tips off an adversary, which gives them a chance to react and rapidly make the incident worse (spread further, change access methods to evade detection, inflict damage/destruction for revenge, cover their tracks, etc.).Note that cleaning up phishing and malicious emails can often be done without tipping off the adversary, but cleaning up host malware and reclaiming control of accounts has a high chance of tipping off the adversary.
These are not easy decisions to make and we have found no substitute for experience in making these judgement calls. The collaborative work environment and culture we have built in our SOC helps immensely as our analysts can tap into each other’s experience to help making these tough calls.
The specific response steps are very dependent on the nature of the attack, but the most common procedures used by our analysts include:
- Client endpoints—SOC analysts can isolate a computer and contact the user directly (or IT operations/helpdesk) to have them initiate a reinstallation procedure.
- Server or applications—SOC analysts typically work with IT operations and/or application owners to arrange rapid remediation of these resources.
- User accounts—We typically reclaim control of these by disabling the account and resetting password for compromised accounts (though these procedures are evolving as a large amount of our users are mostly passwordless using Windows Hello or another form of MFA). Our analysts also explicitly expire all authentication tokens for the user with Microsoft Cloud App Security.
Analysts also review the multi-factor phone number and device enrollment to ensure it hasn’t been hijacked (often contacting the user), and reset this information as needed. - Service Accounts—Because of the high risk of service/business impact, SOC analysts work with the service account owner of record (falling back on IT operations as needed) to arrange rapid remediation of these resources.
- Emails—The attack/phishing emails are deleted (and sometimes cleared to prevent recovering of deleted emails), but we always save a copy of original email in the case notes for later search and analysis (headers, content, scripts/attachments, etc.).
- Other—Custom actions can also be executed based on the nature of the attack such as revoking application tokens, reconfiguring servers and services, and more.
Automation and integration for the win
It’s hard to overstate the value of integrated tools and process automation as these bring so many benefits—improving the analysts daily experience and improving the SOC’s ability to reduce organizational risk.
- Analysts spend less time on each incident, reducing the attacker’s time to operation—measured by mean time to remediate (MTTR).
- Analysts aren’t bogged down in manual administrative tasks so they can react quickly to new detections (reducing mean time to acknowledge—MTTA).
- Analysts have more time to engage in proactive activities that both reduce organization risk and increase morale by keeping them focused on the mission.
Our SOC has a long history of developing our own automation and scripts to make analysts lives easier by a dedicated automation team in our SOC. Because custom automation requires ongoing maintenance and support, we are constantly looking for ways to shift automation and integration to capabilities provided by Microsoft engineering teams (which also benefits our customers). While still early in this journey, this approach typically improves the analyst experience and reduces maintenance effort and challenges.
This is a complex topic that could fill many blogs, but this takes two main forms:
- Integrated toolsets save analysts manual effort during incidents by allowing them to easily navigate multiple tools and datasets. Our SOC relies heavily on the integration of Microsoft Threat Protection (MTP) tools for this experience, which also saves the automation team from writing and supporting custom integration for this.
- Automation and orchestration capabilities reduce manual analyst work by automating repetitive tasks and orchestrating actions between different tools. Our SOC currently relies on an advanced custom SOAR platform and is actively working with our engineering teams (MTP’s AutoIR capability and Azure Sentinel SOAR) on how to shift our learnings and workload onto those capabilities.
After the attacker operation has been fully disrupted, the analyst marks the case as remediated, which is the timestamp signaling the end of MTTR measurement (which started when the analyst began the active investigation in step 2 of the previous blog).
While having a security incident is bad, having the same incident repeated multiple times is much worse.
- Post-incident cleanup—Because lessons aren’t actually “learned” unless they change future actions, our analysts always integrate any useful information learned from the investigation back into our systems. Analysts capture these learnings so that we avoid repeating manual work in the future and can rapidly see connections between past and future incidents by the same threat actors. This can take a number of forms, but common procedures include:
- Indicators of Compromise (IoCs)—Our analysts record any applicable IoCs such as file hashes, malicious IP addresses, and email attributes into our threat intelligence systems so that our SOC (and all customers) can benefit from these learnings.
- Unknown or unpatched vulnerabilities—Our analysts can initiate processes to ensure that missing security patches are applied, misconfigurations are corrected, and vendors (including Microsoft) are informed of “zero day” vulnerabilities so that they can create security patches for them.
- Internal actions such as enabling logging on assets and adding or changing security controls.
Continuous improvement
So the adversary has now been kicked out of the environment and their current operation poses no further risk. Is this the end? Will they retire and open a cupcake bakery or auto repair shop? Not likely after just one failure, but we can consistently disrupt their successes by increasing the cost of attack and reducing the return, which will deter more and more attacks over time. For now, we must assume that adversaries will try to learn from what happened on this attack and try again with fresh ideas and tools.
Because of this, our analysts also focus on learning from each incident to improve their skills, processes, and tooling. This continuous improvement occurs through many informal and formal processes ranging from formal case reviews to casual conversations where they tell the stories of incidents and interesting observations.
As caseload allows, the investigation team also hunts proactively for adversaries when they are not on shift, which helps them stay sharp and grow their skills.
This closes our virtual shift visit for the investigation team. Join us next time as we shift to our Threat hunting team (a.k.a. Tier 3) and get some hard won advice and lessons learned.
…until then, share and enjoy!
P.S. If you are looking for more information on the SOC and other cybersecurity topics, check out previous entries in the series (Part 1 | Part 2a | Part 2b | Part 3a | Part 3b), Mark’s List (https://aka.ms/markslist), and our new security documentation site—https://aka.ms/securtydocs. Be sure to bookmark the Security blog to keep up with our expert coverage on security matters. Also, follow us at @MSFTSecurity for the latest news and updates on cybersecurity. Or reach out to Mark on LinkedIn or Twitter.
READ MORE HERE