From unstructured data to actionable intelligence: Using machine learning for threat intelligence
The security community has become proficient in using indicators of compromise (IoC) feeds for threat intelligence. Automated feeds have simplified the task of extracting and sharing IoCs. However, IoCs like IP addresses, domain names, and file hashes are in the lowest levels of the threat intelligence pyramid; they are relatively easy to access and consume, but they’re also easy for attackers to change to evade detection. IoCs are not enough.
Tactics, techniques, and procedures (TTPs) can enable organizations to extract valuable insights like patterns of attack on an enterprise or industry vertical, or trends of attacker techniques in the overall ecosystem. However, TTPs are at the highest level of the threat intelligence pyramid; this information often comes in the form of unstructured texts like blogs, research papers, and incident response (IR) reports, and the process of gathering and sharing these high-level indicators has remained largely manual.
Automating the processing of unstructured text for threat intelligence can benefit threat analysts and customers alike. At my Black Hat session “Death to the IOC: What’s Next in Threat Intelligence“, I presented a system that automates this process using machine learning and natural language processing (NLP) to identify and extract high-level patterns of attack from unstructured text.
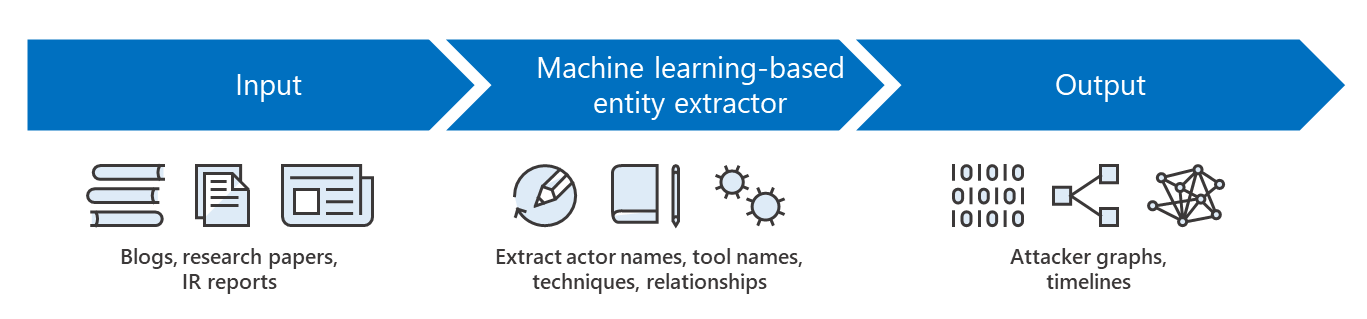
Figure 1. Basic structure of system
Trained on documentation of known threats, this system takes unstructured text as input and extracts threat actors, attack techniques, malware families, and relationships to create attacker graphs and timelines.
Data extraction and machine learning
In natural language processing, named entity extraction is a task that aims to classify phrases into pre-defined categories. This is usually a preprocessing step for other more complex tasks like identifying aliases, relationship extraction between actors and TTPs, etc. In our use case, the categories we want to identify are threat actors, malware families, attack techniques, and relationships between entities.
To train our model, our corpus was comprised of about 2,700 publicly available documents that describe the actions, behaviors, and tools of various threat actors. On average, each document in this corpus contained about two thousand tokens.
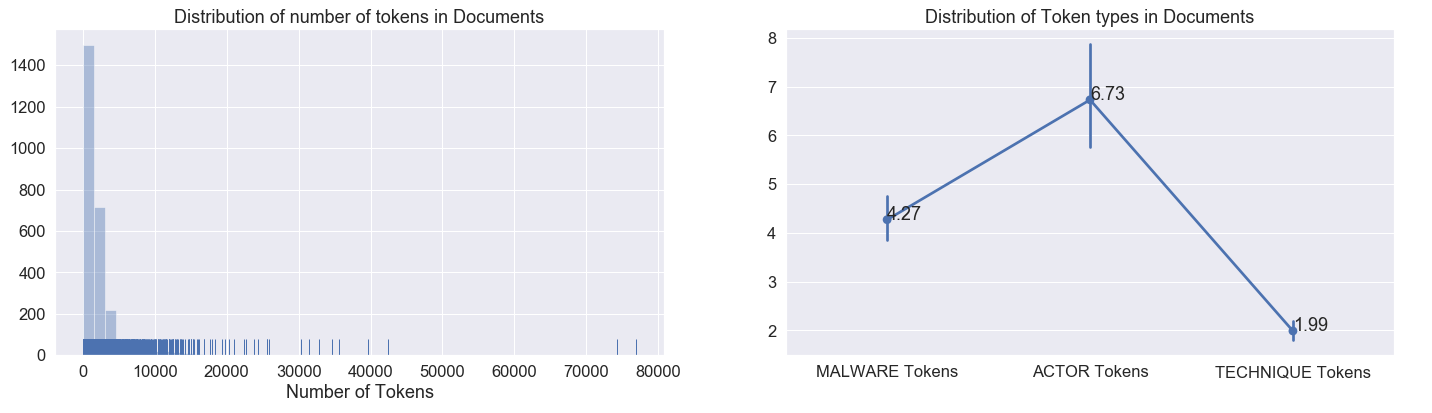
Figure 2. Training data distributions
We also see that the distribution of tokens that fall into one of our predefined categories is very low. On average, only 1% of the tokens are relevant entities. This tells us that we have class imbalance in our data.
Therefore, in addition to using traditional features that are common to natural language processing tasks (for example, lemma, part of speech, orthographic features), we experimented with using custom word embeddings, which allow the identification of relationships between two words that mean the same thing or are used in similar contexts.
Word embeddings are vector representations of words such that the semantic context in which a word appears is captured in the numeric vector. If two words mean the same thing, or are used in the same context frequently, then we would expect the cosine similarity of their word embedding vectors to be high. In other words, in a graphical representation, datapoints for words that mean the same thing or are used in the same context frequently would be relatively close together.
For example, we looked at some clusters of points formed around APT28 and found that the four closest points to it were either aliases (Sofacy, TG-4127) of the threat or were related by attribution (APT29, Dymalloy).
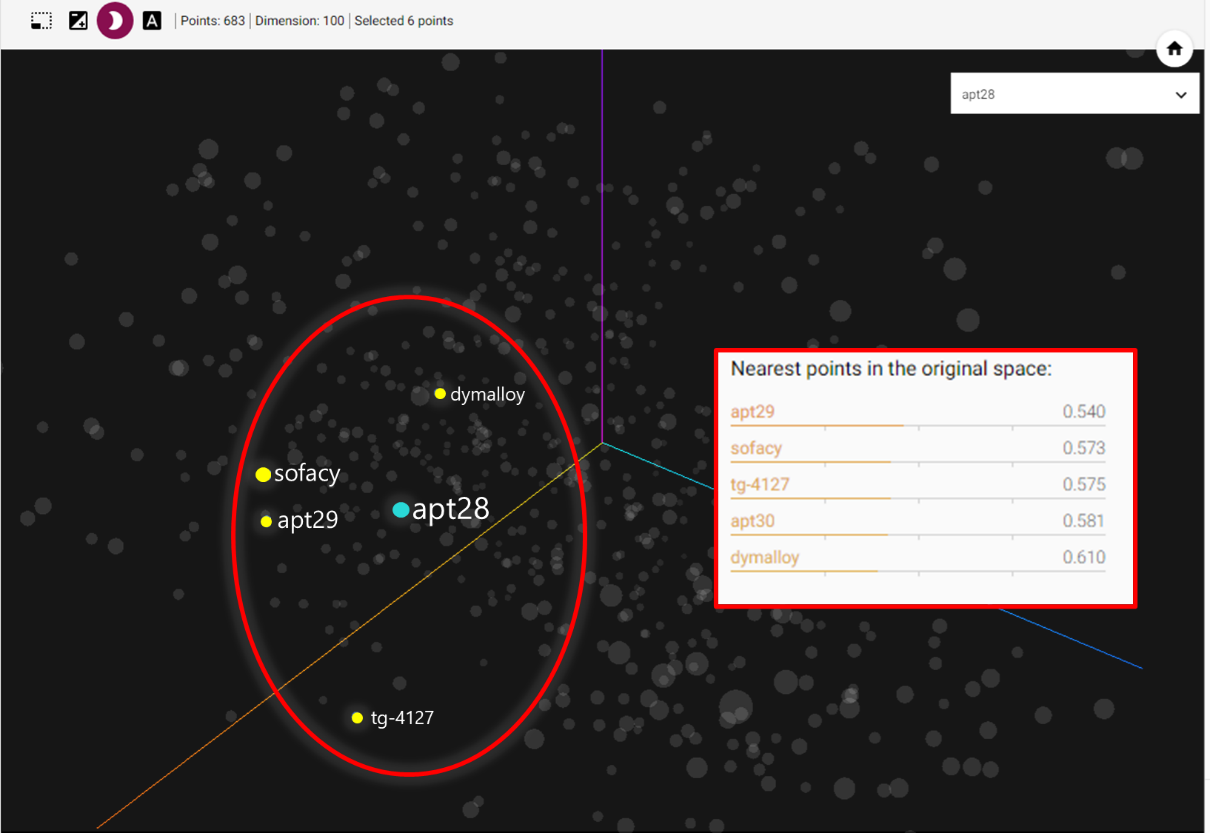
Figure 3. Tensorboard visualization of custom trained embeddings
We experimented with several models that are suited for a sequence labelling problem and measured performance in two ways—on the test dataset and on only the unseen tokens in the test dataset. We found that the experiments trained using conditional random fields (CRFs) trained on traditional and word embedding features have the best performance for both these scenarios.
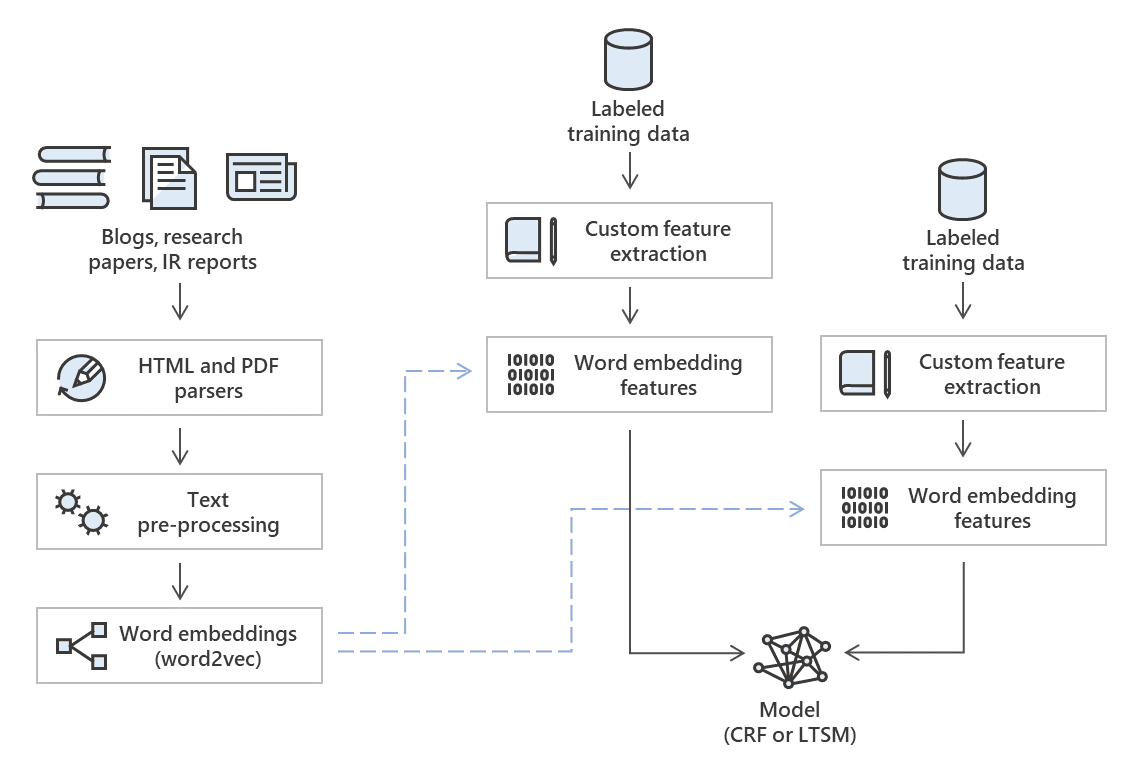
Figure 4. Architecture of training pipeline for extractor system
Machine learning for insightful, actionable intelligence
Using the system we developed, we automatically extracted the techniques known to be used by Emotet, a prominent commodity malware family, as well as a spread of APT actors that public documents refer to as Saffron Rose, Snake, and Muddy Water, and generated the following graph, which shows that there is a significant overlap between some techniques used by commodity malware and those used by APTs.
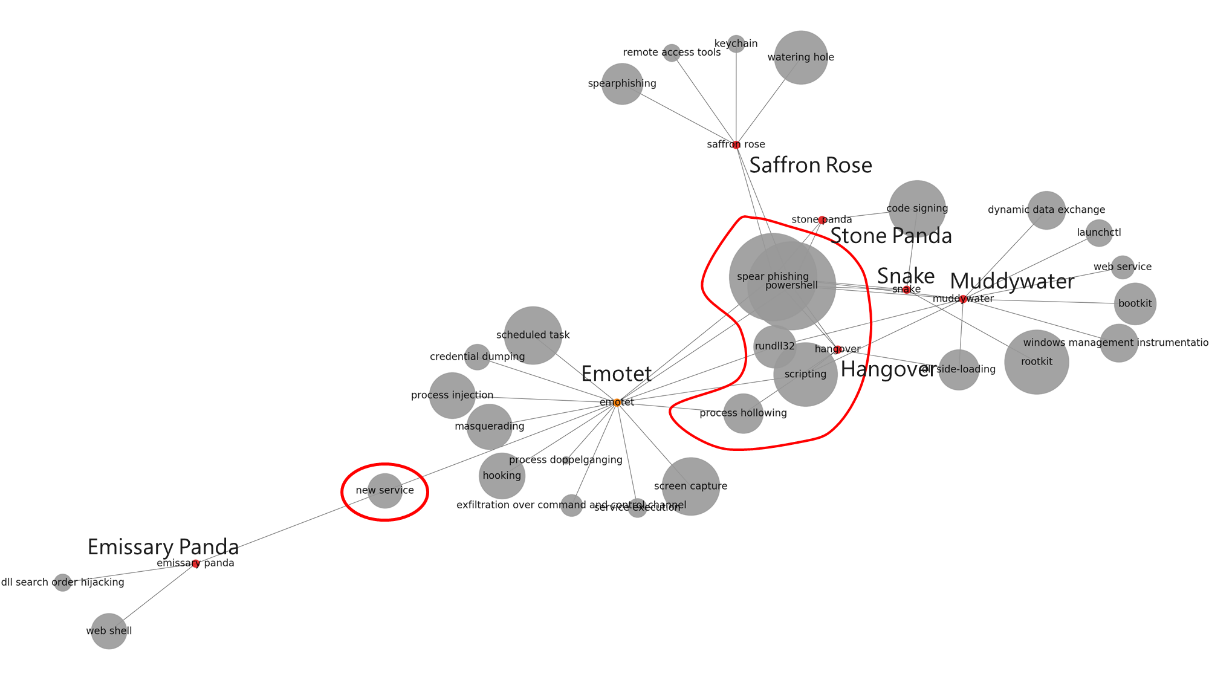
Figure 5. Overlaps in techniques used by commodity malware and APTs
In this graph, we can see that techniques like obfuscated PowerShell, spear-phishing, and process hollowing are not restricted to APTs, but are prevalent in commodity malware. Insights like this can be used by organizations to guide security investments. Organizations can place defensive choke points to detect or prevent these attacker techniques so that they can stop not only annoying commodity malware, but also the high-profile targeted attacks.
At Microsoft, we are continuing to push the boundaries on how machine learning can improve the security posture of our customers. The output of machine learning-backed threat intelligence will show up in the effectiveness of the protection we deliver through Microsoft Defender Advanced Threat Protection (Microsoft Defender ATP) and the broader Microsoft Threat Protection.
In recent months, we have extensively discussed how we’re using machine learning to continuously innovate protections in Microsoft Defender ATP, particularly in hardening against evasion and adversarial attacks. In this blog we showed another application of machine learning: processing the vast amounts of threat intelligence that organizations receive and identifying high-level patterns. More importantly, we’re sharing our approaches so organizations can be inspired to explore more applications of machine learning to improve overall security.
Bhavna Soman (@bsoman3)
Microsoft Defender ATP Research
Talk to us
Questions, concerns, or insights on this story? Join discussions at the Microsoft Defender ATP community.
Read all Microsoft security intelligence blog posts.
Follow us on Twitter @MsftSecIntel.
READ MORE HERE