Deep learning rises: New methods for detecting malicious PowerShell
Scientific and technological advancements in deep learning, a category of algorithms within the larger framework of machine learning, provide new opportunities for development of state-of-the art protection technologies. Deep learning methods are impressively outperforming traditional methods on such tasks as image and text classification. With these developments, there’s great potential for building novel threat detection methods using deep learning.
Machine learning algorithms work with numbers, so objects like images, documents, or emails are converted into numerical form through a step called feature engineering, which, in traditional machine learning methods, requires a significant amount of human effort. With deep learning, algorithms can operate on relatively raw data and extract features without human intervention.
At Microsoft, we make significant investments in pioneering machine learning that inform our security solutions with actionable knowledge through data, helping deliver intelligent, accurate, and real-time protection against a wide range of threats. In this blog, we present an example of a deep learning technique that was initially developed for natural language processing (NLP) and now adopted and applied to expand our coverage of detecting malicious PowerShell scripts, which continue to be a critical attack vector. These deep learning-based detections add to the industry-leading endpoint detection and response capabilities in Microsoft Defender Advanced Threat Protection (Microsoft Defender ATP).
Word embedding in natural language processing
Keeping in mind that our goal is to classify PowerShell scripts, we briefly look at how text classification is approached in the domain of natural language processing. An important step is to convert words to vectors (tuples of numbers) that can be consumed by machine learning algorithms. A basic approach, known as one-hot encoding, first assigns a unique integer to each word in the vocabulary, then represents each word as a vector of 0s, with 1 at the integer index corresponding to that word. Although useful in many cases, the one-hot encoding has significant flaws. A major issue is that all words are equidistant from each other, and semantic relations between words are not reflected in geometric relations between the corresponding vectors.
Contextual embedding is a more recent approach that overcomes these limitations by learning compact representations of words from data under the assumption that words that frequently appear in similar context tend to bear similar meaning. The embedding is trained on large textual datasets like Wikipedia. The Word2vec algorithm, an implementation of this technique, is famous not only for translating semantic similarity of words to geometric similarity of vectors, but also for preserving polarity relations between words. For example, in Word2vec representation:
Madrid – Spain + Italy ≈ Rome
Embedding of PowerShell scripts
Since training a good embedding requires a significant amount of data, we used a large and diverse corpus of 386K distinct unlabeled PowerShell scripts. The Word2vec algorithm, which is typically used with human languages, provides similarly meaningful results when applied to PowerShell language. To accomplish this, we split the PowerShell scripts into tokens, which then allowed us to use the Word2vec algorithm to assign a vectorial representation to each token .
Figure 1 shows a 2-dimensional visualization of the vector representations of 5,000 randomly selected tokens, with some tokens of interest highlighted. Note how semantically similar tokens are placed near each other. For example, the vectors representing -eq, -ne and -gt, which in PowerShell are aliases for “equal”, “not-equal” and “greater-than”, respectively, are clustered together. Similarly, the vectors representing the allSigned, remoteSigned, bypass, and unrestricted tokens, all of which are valid values for the execution policy setting in PowerShell, are clustered together.
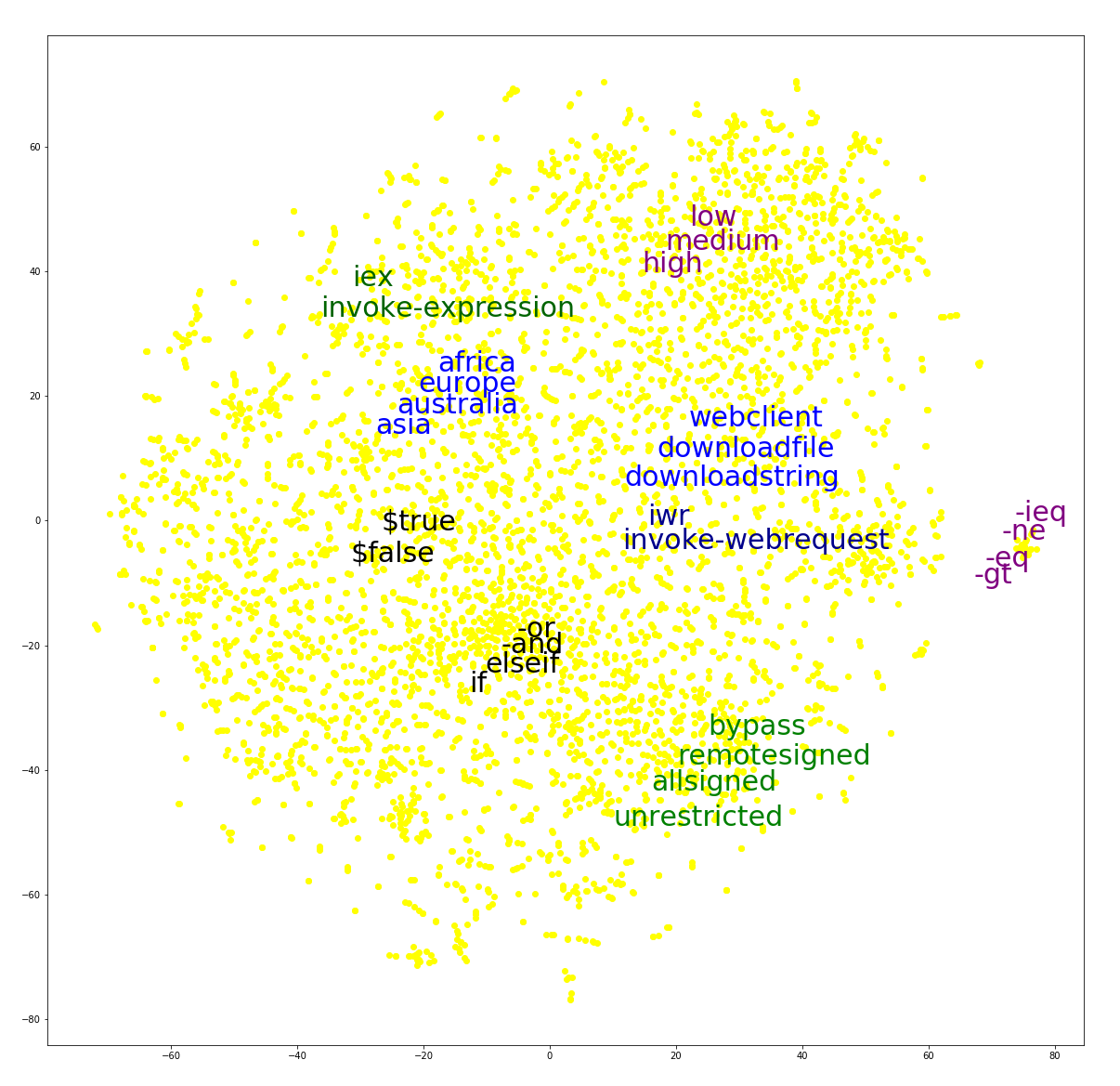
Figure 1. 2D visualization of 5,000 tokens using Word2vec
Examining the vector representations of the tokens, we found a few additional interesting relationships.
Token similarity: Using the Word2vec representation of tokens, we can identify commands in PowerShell that have an alias. In many cases, the token closest to a given command is its alias. For example, the representations of the token Invoke-Expression and its alias IEX are closest to each other. Two additional examples of this phenomenon are the Invoke-WebRequest and its alias IWR, and the Get-ChildItem command and its alias GCI.
We also measured distances within sets of several tokens. Consider, for example, the four tokens $i, $j, $k and $true (see the right side of Figure 2). The first three are usually used to represent a numeric variable and the last naturally represents a Boolean constant. As expected, the $true token mismatched the others – it was the farthest (using the Euclidean distance) from the center of mass of the group.
More specific to the semantics of PowerShell in cybersecurity, we checked the representations of the tokens: bypass, normal, minimized, maximized, and hidden (see the left side of Figure 2). While the first token is a legal value for the ExecutionPolicy flag in PowerShell, the rest are legal values for the WindowStyle flag. As expected, the vector representation of bypass was the farthest from the center of mass of the vectors representing all other four tokens.
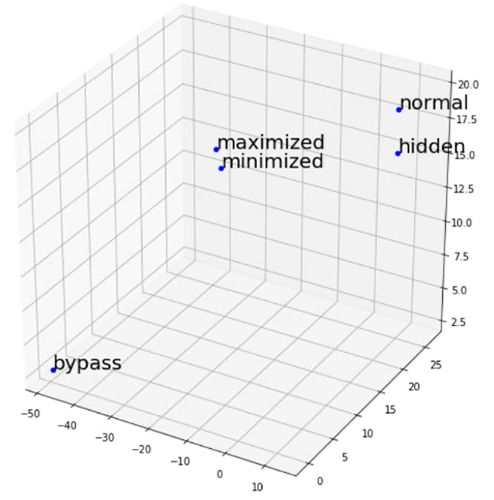
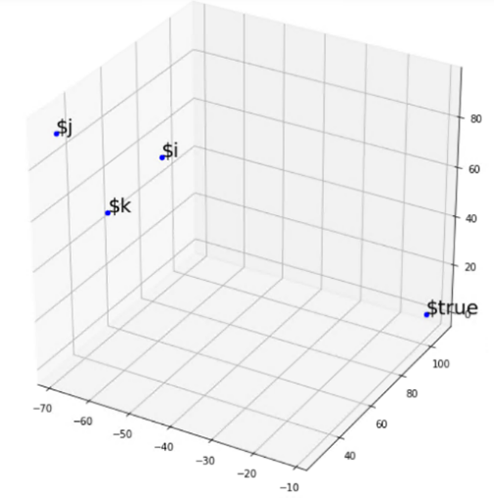
Figure 2. 3D visualization of selected tokens
Linear Relationships: Since Word2vec preserves linear relationships, computing linear combinations of the vectorial representations results in semantically meaningful results. Below are a few interesting relationships we found:
high – $false + $true ≈’ low
‘-eq’ – $false + $true ‘≈ ‘-neq’
DownloadFile – $destfile + $str ≈’ DownloadString ‘
Export-CSV’ – $csv + $html ‘≈ ‘ConvertTo-html’
‘Get-Process’-$processes+$services ‘≈ ‘Get-Service’
In each of the above expressions, the sign ≈ signifies that the vector on the right side is the closest (among all the vectors representing tokens in the vocabulary) to the vector that is the result of the computation on the left side.
Detection of malicious PowerShell scripts with deep learning
We used the Word2vec embedding of the PowerShell language presented in the previous section to train deep learning models capable of detecting malicious PowerShell scripts. The classification model is trained and validated using a large dataset of PowerShell scripts that are labeled “clean” or “malicious,” while the embeddings are trained on unlabeled data. The flow is presented in Figure 3.
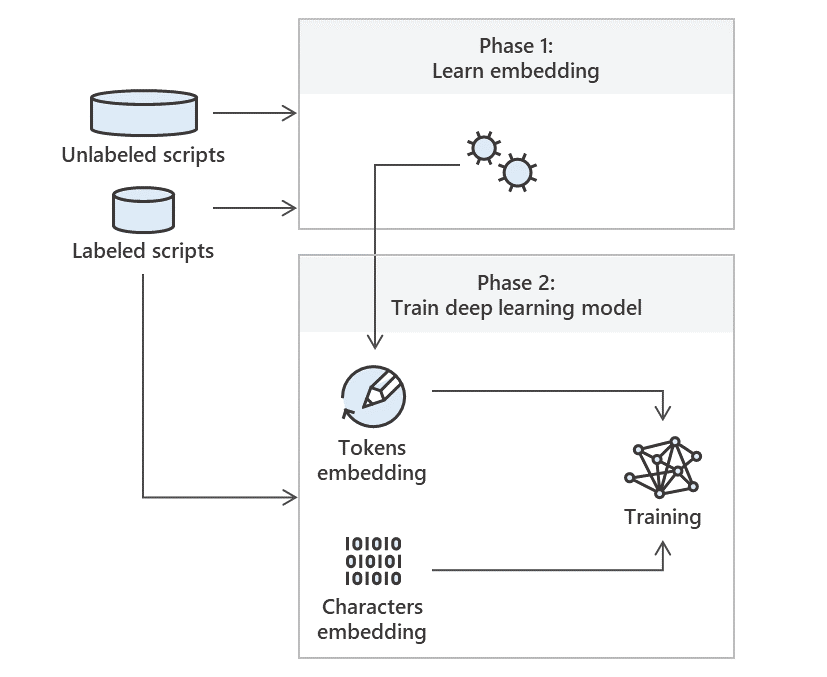
Figure 3 High-level overview of our model generation process
Using GPU computing in Microsoft Azure, we experimented with a variety of deep learning and traditional ML models. The best performing deep learning model increases the coverage (for a fixed low FP rate of 0.1%) by 22 percentage points compared to traditional ML models. This model, presented in Figure 4, combines several deep learning building blocks such as Convolutional Neural Networks (CNNs) and Long Short-Term Memory Recurrent Neural Networks (LSTM-RNN). Neural networks are ML algorithms inspired by biological neural systems like the human brain. In addition to the pretrained embedding described here, the model is provided with character-level embedding of the script.
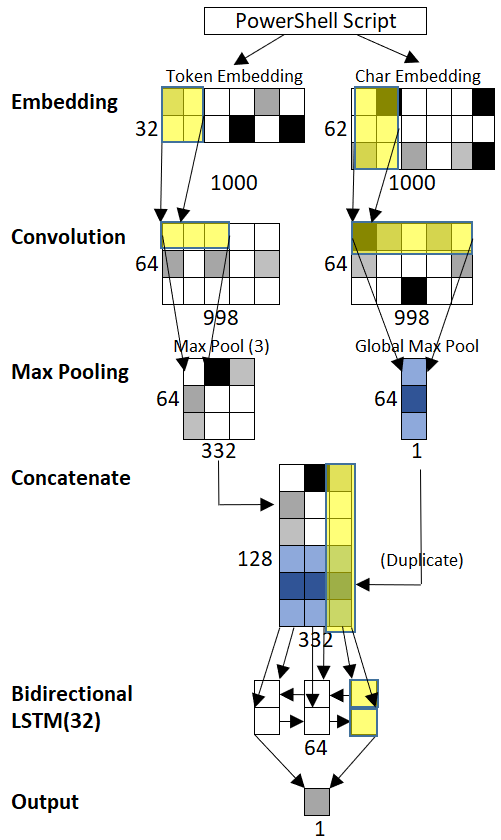
Figure 4 Network architecture of the best performing model
Real-world application of deep learning to detecting malicious PowerShell
The best performing deep learning model is applied at scale using Microsoft ML.Net technology and ONNX format for deep neural networks to the PowerShell scripts observed by Microsoft Defender ATP through the AMSI interface. This model augments the suite of ML models and heuristics used by Microsoft Defender ATP to protect against malicious usage of scripting languages.
Since its first deployment, this deep learning model detected with high precision many cases of malicious and red team PowerShell activities, some undiscovered by other methods. The signal obtained through PowerShell is combined with a wide range of ML models and signals of Microsoft Defender ATP to detect cyberattacks.
The following are examples of malicious PowerShell scripts that deep learning can confidently detect but can be challenging for other detection methods:

Figure 5. Heavily obfuscated malicious script

Figure 6. Obfuscated script that downloads and runs payload

Figure 7. Script that decrypts and executes malicious code
Enhancing Microsoft Defender ATP with deep learning
Deep learning methods significantly improve detection of threats. In this blog, we discussed a concrete application of deep learning to a particularly evasive class of threats: malicious PowerShell scripts. We have and will continue to develop deep learning-based protections across multiple capabilities in Microsoft Defender ATP.
Development and productization of deep learning systems for cyber defense require large volumes of data, computations, resources, and engineering effort. Microsoft Defender ATP combines data collected from millions of endpoints with Microsoft computational resources and algorithms to provide industry-leading protection against attacks.
Stronger detection of malicious PowerShell scripts and other threats on endpoints using deep learning mean richer and better-informed security through Microsoft Threat Protection, which provides comprehensive security for identities, endpoints, email and data, apps, and infrastructure.
Shay Kels and Amir Rubin
Microsoft Defender ATP team
Additional references:
READ MORE HERE