CISO series: Lessons learned from the Microsoft SOC—Part 3b: A day in the life
The Lessons learned from the Microsoft SOC blog series is designed to share our approach and experience with security operations center (SOC) operations. We share strategies and learnings from our SOC, which protects Microsoft, and our Detection and Response Team (DART), who helps our customers address security incidents. For a visual depiction of our SOC philosophy, download our Minutes Matter poster.
For the next two installments in the series, we’ll take you on a virtual shadow session of a SOC analyst, so you can see how we use security technology. You’ll get to virtually experience a day in the life of these professionals and see how Microsoft security tools support the processes and metrics we discussed earlier. We’ll primarily focus on the experience of the Investigation team (Tier 2) as the Triage team (Tier 1) is a streamlined subset of this process. Threat hunting will be covered separately.

General impressions
Newcomers to the facility often remark on how calm and quiet our SOC physical space is. It looks and sounds like a “normal” office with people going about their job in a calm professional manner. This is in sharp contrast to the dramatic moments in TV shows that use operations centers to build tension/drama in a noisy space.
Nature doesn’t have edges
We have learned that the real world is often “messy” and unpredictable, and the SOC tends to reflect that reality. What comes into the SOC doesn’t always fit into the nice neat boxes, but a lot of it follows predictable patterns that have been forged into standard processes, automation, and (in many cases) features of Microsoft tooling.
Routine front door incidents
The most common attack patterns we see are phishing and stolen credentials attacks (or minor variations on them):
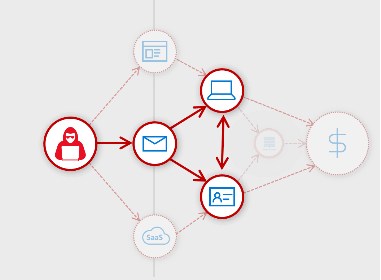
- Phishing email → Host infection → Identity pivot:
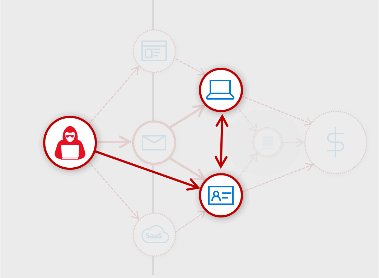
- Stolen credentials → Identity pivot → Host infection:
While these aren’t the only ways attackers gain access to organizations, they’re the most prevalent methods mastered by most attackers. Just as martial artists start by mastering basic common blocks, punches, and kicks, SOC analysts and teams must build a strong foundation by learning to respond rapidly to these common attack methods.
As we mentioned earlier in the series, it’s been over two years since network-based detection has been the primary method for detecting an attack. We attribute this primarily to investments that improved our ability to rapidly remediate attacks early with host/email/identity detections. There are also fundamental challenges with network-based detections (they are noisy and have limited native context for filtering true vs. false positives).
Analyst investigation process
Once an analyst settles into the analyst pod on the watch floor for their shift, they start checking the queue of our case management system for incidents (not entirely unlike phone support or help desk analysts would).
While anything might show up in the queue, the process for investigating common front door incidents includes:
- Alert appears in the queue—After a threat detection tool detects a likely attack, an incident is automatically created in our case management system. The Mean Time to Acknowledge (MTTA) measurement of SOC responsiveness begins with this timestamp. See Part 1: Organization for more information on key SOC metrics.
Basic threat hunting helps keep a queue clean and tidy
Require a 90 percent true positive rate for alert sources (e.g., detection tools and types) before allowing them to generate incidents in the analyst queue. This quality requirement reduces the volume of false positive alerts, which can lead to frustration and wasted time. To implement, you’ll need to measure and refine the quality of alert sources and create a basic threat hunting process. A basic threat hunting process leverages experienced analysts to comb through alert sources that don’t meet this quality bar to identify interesting alerts that are worth investigating. This review (without requiring full investigation of each one) helps ensure that real incident detections are not lost in the high volume of noisy alerts. It can be a simple part time process, but it does require skilled analysts that can apply their experience to the task.
- Own and orient—The analyst on shift begins by taking ownership of the case and reading through the information available in the case management tool. The timestamp for this is the end of the MTTA responsiveness measurement and begins the Mean Time to Remediate (MTTR) measurement.
Experience matters
A SOC is dependent on the knowledge, skills, and expertise of the analysts on the team. The attack operators and malware authors you defend against are often adaptable and skilled humans, so no prescriptive textbook or playbook on response will stay current for very long. We work hard to take good care of our people—giving them time to decompress and learn, recruiting them from diverse backgrounds that can bring fresh perspectives, and creating a career path and shadowing programs that encourage them to learn and grow.
- Check out the host—Typically, the first priority is to identify affected endpoints so analysts can rapidly get deep insight. Our SOC relies on the Endpoint Detection and Response (EDR) functionality in Microsoft Defender Advanced Threat Protection (ATP) for this.
Why endpoint is important
Our analysts have a strong preference to start with the endpoint because:
- Endpoints are involved in most attacks—Malware on an endpoint represents the sole delivery vehicle of most commodity attacks, and most attack operators still rely on malware on at least one endpoint to achieve their objective. We’ve also found the EDR capabilities detect advanced attackers that are “living off the land” (using tools deployed by the enterprise to navigate). The EDR functionality in Microsoft Defender ATP provides visibility into normal behavior that helps detect unusual command lines and process creation events.
- Endpoint offers powerful insights—Malware and its behavior (whether automated or manual actions) on the endpoint often provides rich detailed insight into the attacker’s identity, skills, capabilities, and intentions, so it’s a key element that our analysts always check for.
Identifying the endpoints affected by this incident is easy for alerts raised by the Microsoft Defender ATP EDR, but may take a few pivots on an email or identity sourced alert, which makes integration between these tools crucial.
- Scope out and fill in the timeline—The analyst then builds a full picture and timeline of the related chain of events that led to the alert (which may be an adversary’s attack operation or false alarm positive) by following leads from the first host alert. The analyst travels along the timeline:
- Backward in time—Track backward to identify the entry point in the environment.
- Forward in time—Follow leads to any devices/assets an attacker may have accessed (or attempted to access).
Our analysts typically build this picture using the MITRE ATT&CK™ model (though some also adhere to the classic Lockheed Martin Cyber Kill Chain®).
True or false? Art or science?
The process of investigation is partly a science and partly an art. The analyst is ultimately building a storyline of what happened to determine whether this chain of events is the result of a malicious actor (often attempting to mask their actions/nature), a normal business/technical process, an innocent mistake, or something else.
This investigation is a repetitive process. Analysts identify potential leads based on the information in the original report, follow those leads, and evaluate if the results contribute to the investigation.
Analysts often contact users to identify whether they performed an anomalous action intentionally, accidentally, or was not done by them at all.
Running down the leads with automation
Much like analyzing physical evidence in a criminal investigation, cybersecurity investigations involve iteratively digging through potential evidence, which can be tedious work. Another parallel between cybersecurity and traditional forensic investigations is that popular TV and movie depictions are often much more exciting and faster than the real world.
One significant advantage of investigating cyberattacks is that the relevant data is already electronic, making it easier to automate investigation. For many incidents, our SOC takes advantage of security orchestration, automation, and remediation (SOAR) technology to automate investigation (and remediation) of routine incidents. Our SOC relies heavily on the AutoIR functionality in Microsoft Threat Protection tools like Microsoft Defender ATP and Office 365 ATP to reduce analyst workload. In our current configuration, some remediations are fully automatic and some are semi-automatic (where analysts review the automated investigations and propose remediation before approving execution of it).
Document, document, document
As the analyst builds this understanding, they must capture a complete record with their conclusions and reasoning/evidence for future use (case reviews, analyst self-education, re-opening cases that are later linked to active attacks, etc.).
As our analyst develops information on an incident, they capture the common, most relevant details quickly into the case such as:
- Alert info: Alert links and Alert timeline
- Machine info: Name and ID
- User info
- Event info
- Detection source
- Download source
- File creation info
- Process creation
- Installation/Persistence method(s)
- Network communication
- Dropped files
Fusion and integration avoid wasting analyst time
Each minute an analyst wastes on manual effort is another minute the attacker has to spread, infect, and do damage during an attack operation. Repetitive manual activity also creates analyst toil, increases frustration, and can drive interest in finding a new job or career.
We learned that several technologies are key to reducing toil (in addition to automation):
- Fusion—Adversary attack operations frequently trip multiple alerts in multiple tools, and these must be correlated and linked to avoid duplication of effort. Our SOC has found significant value from technologies that automatically find and fuse these alerts together into a single incident. Azure Security Center and Microsoft Threat Protection include these natively.
- Integration—Few things are more frustrating and time consuming than having to switch consoles and tools to follow a lead (a.k.a., swivel chair analytics). Switching consoles interrupts their thought process and often requires manual tasks to copy/paste information between tools to continue their work. Our analysts are extremely appreciative of the work our engineering teams have done to bring threat intelligence natively into Microsoft’s threat detection tools and link together the consoles for Microsoft Defender ATP, Office 365 ATP, and Azure ATP. They’re also looking forward to (and starting to test) the Microsoft Threat Protection Console and Azure Sentinel updates that will continue to reduce the swivel chair analytics.
Stay tuned for the next segment in the series, where we’ll conclude our investigation, remediate the incident, and take part in some continuous improvement activities.
Learn more
In the meantime, bookmark the Security blog to keep up with our expert coverage on security matters and follow us at @MSFTSecurity for the latest news and updates on cybersecurity.
To learn more about SOCs, read previous posts in the Lessons learned from the Microsoft SOC series, including:
Watch the CISO Spotlight Series: Passwordless: What’s It Worth.
Also, see our full CISO series and download our Minutes Matter poster for a visual depiction of our SOC philosophy.
READ MORE HERE